Install TensorFlow on Apple Silicon Macs
First we install TensorFlow on the M1, then we run a small functional test and finally we do a benchmark comparison with an AWS system.
The installation of TensorFlow is very simple#
First, install an ARM version of Python. Recommended (as of 03.2021) is Python 3.8. Version 3.9 is currently not compatible. You can simply install PyCharm (free community version for M1 Mac). This will give you a fully functional Python installation.
Once you have installed Python, do the following#
Open a terminal on your Mac and copy the following line of code into it. This will download TensorFlow and install it in a folder of your choice. Alternatively you can select the default folder.
Default-Folder: /Users/customer/tensorflow_macos_venv/
You should get the following message afterwards:
The next step is to activate your newly created Virtual Environment. Copy the following command into your terminal:
Important: Do not forget the period at the beginning!
Your prompt should have changed like this now:
Now you can start python and import TensorFlow with import tensorflow as tf. You can see with the command tf.__version__ if everything worked. Your output should look like this now:
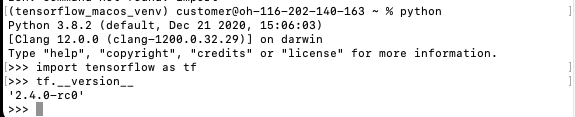
With this the basic installation of TensorFlow is already done.
More information about the current state of the TensorFlow release and which features are not yet supported can be found on the repository page: https://github.com/tensorflow/tensorflow
A small basic application to see if everything works properly#
For this we use the MNIST dataset with handwritten numbers. One of the most popular DataSets to enter the world of Machine Learning and Image Classification. The corresponding Jupyter notebook with more details is available here:
https://www.tensorflow.org/tutorials/quickstart/beginner
Output: (The output values may differ slightly, since the forecast is of course recreated)
Output:
You may get a warning message:
tensorflow/core/platform/profile_utils/cpu_utils.cc:126] Failed to get CPU frequency: 0 Hz
TensorFlow for Apple Silicon is currently (March 2021) still in an alpha version and certainly still contains one or two bugs. However, most of it already works very well and very fast. Often more than 3s are needed per epoch with Intel CPU and GPU.
Output:
Output:
Output:
Perfect!
The Benchmark#
Now it gets really exciting! How does our small model with 8 GB RAM perform in the benchmark?
We take as comparison the benchmark of https://www.neuraldesigner.com/blog/training-speed-comparison-gpu-approximation
The data from the comparison computer at AWS:

Theoretically, our little Mac should score much worse, since this is a real ML monster, we are curious!
The specs of our Mac Mini M1:

To run the example Pandas and Numpyy must be installed.
The installation of pandas fails if you try to do it via pip install pandas. For a successful installation numpy cython is necessary. Here are the instructions:
The data used is downloadable from the link above and here is the code used, identical to the benchmark:
First, the results of the AWS Windows PC:
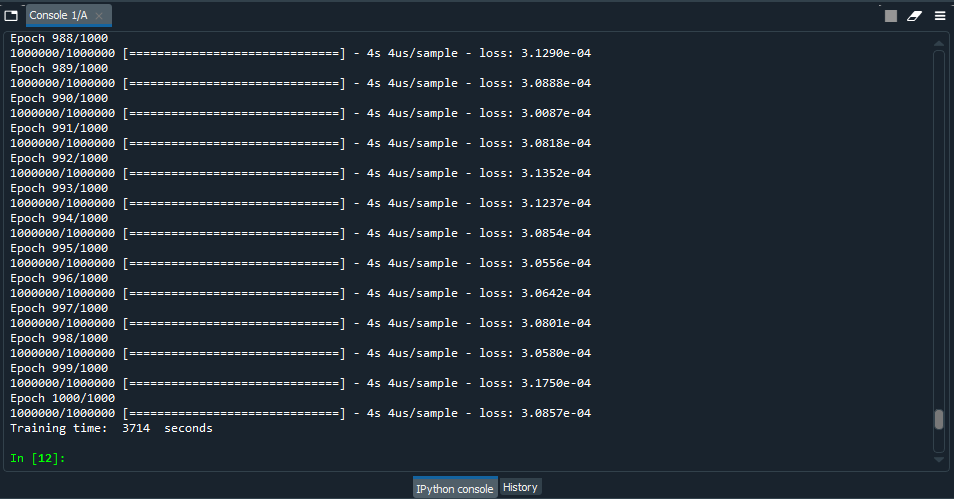
Training time at 1000 epochs was 3714 seconds with an error of 0.0003857 and an average CPU usage of 45%. That's pretty fast!
Now let's give our little Mac Mini a traning:

For its specifications, the result is not bad, but I actually expected more from the new chip. Training time at 1000 epochs was 11814 seconds. Apparently there is still some need for optimization as far as large trainig sets are concerned. The same experience was also made in this blog: https://medium.com/analytics-vidhya/m1-mac-mini-scores-higher-than-my-nvidia-rtx-2080ti-in-tensorflow-speed-test-9f3db2b02d74
Then let's try the small training set from the blog above:
The result is similar to the blog post, a bit slower because I had a few other applications open:
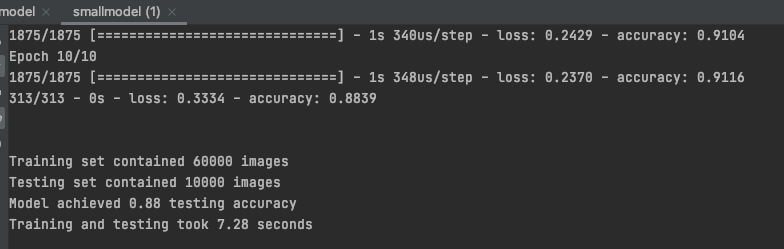
These values are quite respectable and TensorFlow on ARM is only in the early stages. I am very confident that the performance will improve significantly. Especially for large training sets. And very important: The power consumption and heat generation is minimal! This is a huge advantage for the environment and not least for the wallet!