TensorFlow auf Apple Silicon Macs installieren
Als erstes installieren wir TensorFlow auf dem M1, dann lassen wir einen kleinen Funktionstest laufen und zum Schluss kommt ein Benchmark-Vergleich mit einem AWS-System.
Die Installation von TensorFlow ist sehr einfach
Installiere Dir eine ARM-Version von Python. Zu empfehlen (03.2021) Python 3.8. Version 3.9 ist aktuell noch nicht kompatibel. Du kannst dazu zum Beispiel einfach PyCharm (kostenlose Community-Version für M1 Mac) installieren. Damit bekommst du eine voll funktionsfähige Python-Installation mitgeliefert.
Sobald du Python installiert hast, gehe folgendermaßen vor
Öffne ein Terminal auf deinem Mac und kopiere folgende Code-Zeile hinein. Damit wird TensorFlow heruntergeladen und in einem Ordner deiner Wahl installiert. Alternatv kannst du auch den Default-Ordner belassen.
/bin/bash -c "$(curl -fsS https://raw.githubusercontent.com/apple/tensorflow_macos/master/scripts/download_and_install.sh)"
Default-Ordner: /Users/customer/tensorflow_macos_venv/
Du solltest danach folgende Meldung erhalten:
TensorFlow and TensorFlow Addons with ML Compute for macOS 11.0 successfully installed.
Der nächste Schritt ist, dein bereits erstelltes Virtual Environment zu aktivieren. Kopiere dazu folgendes Kommando in dein Terminal:
. tensorflow_macos_venv/bin/activate`
Wichtig: nicht den Punkt am Anfang vergessen!
Dein Prompt sollte sich jetzt so verändert haben:
(tensorflow_macos_venv) customer@oh-xxx-xxx-xxx-xxx
Nun kannst du python aufrufen und mit import tensorflow as tf TensorFlow importieren. Ob alles geklappt hat, siehst du mit dem Befehl tf.__version__. Deine Ausgabe sollte nun so ähnlich ausschauen:
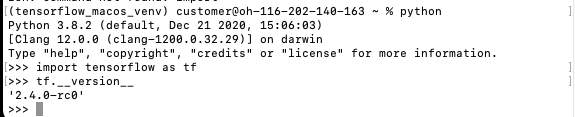
Damit ist die Basisinstallation von TensorFlow schon fertig
Weitere Information zu dem aktuellen Stand des TensorFlow-Release und welche Funktion noch nicht unterstützt werden findest du auf der Repository-Seite: https://github.com/tensorflow/tensorflow
Eine kleine Basisanwendung, um zu sehen ob alles richtig funktioniert
Dafür verwenden wir das MNIST-Dataset mit handgeschriebenen Zahlen. Eines der populärsten DataSets um in die Welt des Machine Learning und Image Classification einzusteigen. Das zugehörige Jupyter-Notebook mit weiteren Details gibt es hier:
https://www.tensorflow.org/tutorials/quickstart/beginner
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0`
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])`
predictions = model(x_train[:1]).numpy()
print(predictions)
Output: (Die ausgegeben Werte können etwas abweichen, da die Vorhersage natürlich neu erstellt wird)
[[ 0.50077856 0.46635205 -0.04764563 0.0613101 -1.2088307 0.2828893
0.37654606 -0.20382181 -0.903594 0.04570436]]
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
print(loss_fn(y_train[:1], predictions).numpy())Output:
Output:
2.0790117
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])
print(model.fit(x_train, y_train, epochs=5))
Möglicherweise bekommt du eine Warnmeldung:
tensorflow/core/platform/profile_utils/cpu_utils.cc:126] Failed to get CPU frequency: 0 Hz
TensorFlow für Apple Silicon ist aktuell (März 2021) noch in einer Alpha-Version und der ein oder andere Bug sicher noch enthalten. Jedoch funktioniert das meiste bereits sehr gut und sehr schnell. Oftmals werden mit Intel CPU und GPU pro Epoche mehr als 3s benötigt.
Output:
Epoch 1/5
1875/1875 [==============================] - 1s 357us/step - loss: 0.5219 - accuracy: 0.8408
Epoch 2/5
1875/1875 [==============================] - 1s 358us/step - loss: 0.2014 - accuracy: 0.9393
Epoch 3/5
1875/1875 [==============================] - 1s 360us/step - loss: 0.1568 - accuracy: 0.9521
Epoch 4/5
1875/1875 [==============================] - 1s 361us/step - loss: 0.1345 - accuracy: 0.9591
Epoch 5/5
1875/1875 [==============================] - 1s 355us/step - loss: 0.1196 - accuracy: 0.9638
<tensorflow.python.keras.callbacks.History object at 0x10f663670>
print(model.evaluate(x_test, y_test, verbose=2))
Output:
313/313 - 0s - loss: 2.4059 - accuracy: 0.0905
[2.405911684036255, 0.09049999713897705]
probability_model = tf.keras.Sequential([
model,
tf.keras.layers.Softmax()
])
print(probability_model(x_test[:5]))
Output:
tf.Tensor(
[[0.05310559 0.05768739 0.14392214 0.04889955 0.11977675 0.17591962
0.08728485 0.12659737 0.06151325 0.12529361]
[0.04891613 0.02110806 0.16333279 0.20522392 0.10033478 0.05052991
0.11514534 0.06312083 0.12917142 0.1031168 ]
[0.09449682 0.06958783 0.1278147 0.086374 0.09083354 0.13517839
0.08620356 0.09317197 0.09092354 0.1254157 ]
[0.06520557 0.04453962 0.1340602 0.08413237 0.07909293 0.10583147
0.1035168 0.06752329 0.14527227 0.17082547]
[0.04817105 0.05779015 0.13250412 0.08222131 0.09708948 0.14379048
0.05646132 0.1505455 0.12961316 0.10181346]],
shape=(5, 10), dtype=float32)
Perfekt!
Der Benchmark
Jetzt wird es richtig spannend! Wie schneidet unser kleines Modell mit 8 GB RAM im Benchmark ab?
Wir nehmen als Vergleich den Benchmark von https://www.neuraldesigner.com/blog/training-speed-comparison-gpu-approximation
Die Daten des Vergleichscomputers bei AWS:

Theoretisch müsste unser kleiner Mac deutlich schlechter abschneiden, da es sich hier um ein echtes ML Monster handelt, wir sind gespannt!
Die Daten unseres Mac Mini M1:

Um das Beispiel auszuführen muss Pandas und Numpyy installiert sein.
Die Installation von Pandas schlägt fehl, wenn man sie über pip install pandas vornehmen möchte. Für eine erfolgreiche Installation ist numpy cython Notwendig. Hier die Anleitung:
pip install --upgrade pip
pip install numpy cython
git clone https://github.com/pandas-dev/pandas.git
cd pandas
python3 setup.py install
Die verwendeten Daten sind unter dem obigen Link herunterladbar und hier der verwendete Code, identisch zum Benchmark:
import tensorflow as tf
import pandas as pd
import time
import numpy as np
# read data float32
start_time = time.time()
filename = ""/Users/customer/Documents/R_new.csv
df_test = pd.read_csv(filename, nrows=100)
float_cols = [c for c in df_test if df_test[c].dtype == "float64"]
float32_cols = {c: np.float32 for c in float_cols}
data = pd.read_csv(filename, engine='c', dtype=float32_cols)
print("Loading time: ", round(time.time() - start_time), " seconds")
x = data.iloc[:, :-1].values
y = data.iloc[:, [-1]].values
initializer = tf.keras.initializers.RandomUniform(minval=-1., maxval=1.)
# build model
model = tf.keras.models.Sequential([tf.keras.layers.Dense(1000,
activation='tanh',
kernel_initializer=initializer,
bias_initializer=initializer),
tf.keras.layers.Dense(1,
activation='linear',
kernel_initializer=initializer,
bias_initializer=initializer)])
# compile model
model.compile(optimizer='adam', loss='mean_squared_error')
# train model
start_time = time.time()
history = model.fit(x, y, batch_size=1000, epochs=1000)
print("Training time: ", round(time.time() - start_time), " seconds")
Als erstes die Werte des AWS Windows-PC:
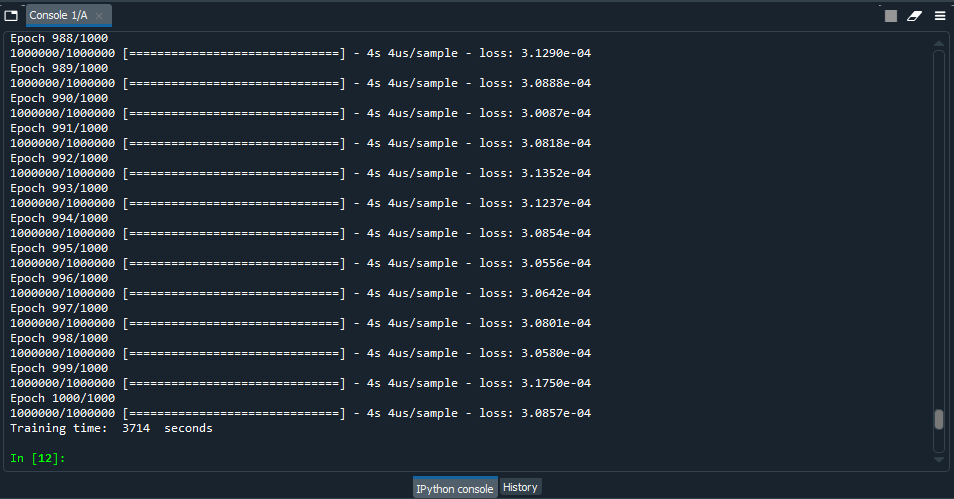
Trainigszeit bei 1000 Epochen war 3714 Sekunden mit einem Fehler von 0.0003857 und einer durchschnittlen CPU-Nutzung von 45%. Das ist ziemlich schnell!
Jetzt lassen wir mal unseren kleinen Mac Mini trainieren:

Für seine Spezifikation ist das Ergebnis nicht übel, aber eigentlich habe ich mir mehr von dem neuen Chip erwartet. Trainingszeit bei 1000 Epochen war 11814 Sekunden. Anscheinend gibt es noch etwas Optimierungsbedarf, was große Trainigssets angeht. Die gleiche Erfahrung wurde in diesem Blog auch gemacht: https://medium.com/analytics-vidhya/m1-mac-mini-scores-higher-than-my-nvidia-rtx-2080ti-in-tensorflow-speed-test-9f3db2b02d74
Dann lass uns doch mal das kleine Trainigsset aus obigem Blog probieren:
#import libraries
import tensorflow as tf
import time
#download fashion mnist dataset
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
train_set_count = len(train_labels)
test_set_count = len(test_labels)
#setup start time
t0 = time.time()
#normalize images
train_images = train_images / 255.0
test_images = test_images / 255.0
#create ML model
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
#compile ML model
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
#train ML model
model.fit(train_images, train_labels, epochs=10)
#evaluate ML model on test set
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
#setup stop time
t1 = time.time()
total_time = t1-t0
#print results
print('\n')
print(f'Training set contained {train_set_count} images')
print(f'Testing set contained {test_set_count} images')
print(f'Model achieved {test_acc:.2f} testing accuracy')
print(f'Training and testing took {total_time:.2f} seconds')
Das Ergebnis ist ähnlich wie in dem Blog, ein bischen langsamer da ich Ausnahmsweise noch ein paar andere Anwendungen offen hatte:
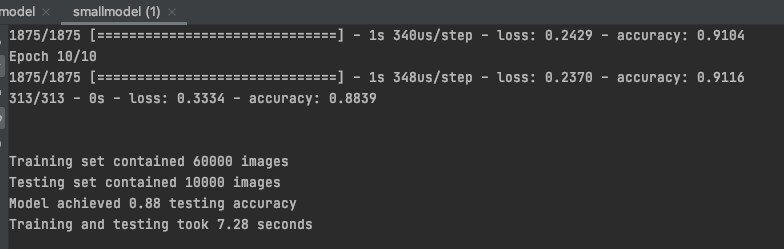
Diese Werte können sich durchaus sehen lassen und TensorFlow auf ARM ist erst in der Anfangsphase. Ich bin sehr zuversichtlich, dass die Performance noch deutlich besser wird. Insbesondere bei großen Trainingssets. Und ganz wichtig: Der Stromverbrauch und die Hitzeentwicklung ist minimal! Das ist ein riesiger Vorteil für die Umwelt und nicht zuletzt für den Geldbeutel!